
Originally posted on the Shapeways Tech blog

Storage. Every tech venture needs it to some degree, so much so that there are entire businesses built around providing it. At Shapeways, we manage our own hardware in our own data centers, and therefore provide our own storage services and solutions. We host well over 100TB of content (and growing every day), comprised of user-provided 3d models, images, renders, and all the digital nuts and bolts required to bring our users’ digital creations to life in the real world.
ZFS on Linux - A Very Brief Introduction
Shapeways has iterated through several storage solutions as our needs have evolved, and are currently using ZFS on linux as the base of our system. ZoL is fast, redundant, supports replication, and offers compression which is extremely effective on the type of content we’re storing. I’m not going to go into all the specifics about our ZoL configuration (we’ll get that in a different post), but suffice to say that it’s been great for us….for the most part. This is the story of one of the struggles we’ve had (caused by our lack of understanding of ZoL’s inner operations), how we diagnosed and addressed the issue, and how we’ve protected ourselves from it occurring again. My hope here is that this will save someone a few sleepless nights somewhere down the road :smile:
Code Red
On a Monday afternoon much like any other, our normally performant website began to slow down. A lot. Pages with 200ms server response time shot up to seconds. Slower, more content-heavy pages, tens of seconds, causing our DNS and CDN provider to actually consider us offline. We began triaging immediately, but were having difficulty pinpointing the issue. Datadog was reporting increased load on all major systems, including webnode, database, model processing, and storage. IOPS on our primary storage server were up, ok. Context switching was high, but not through the roof. Actual CPU utilization, however…fine? There were a great many processes, but almost all were idle or waiting. So, everything is slow, and there’s no clear indication why. The blocking processes pointed at storage, but we didn’t see any signs in our monitoring that storage was the issue. We knew that ZoL would start to run into issues if we ever got more than 85% full on any of our ZFS tanks (related to how ZoL uses CPU to search for free space), but we weren’t even close. So, wtf?
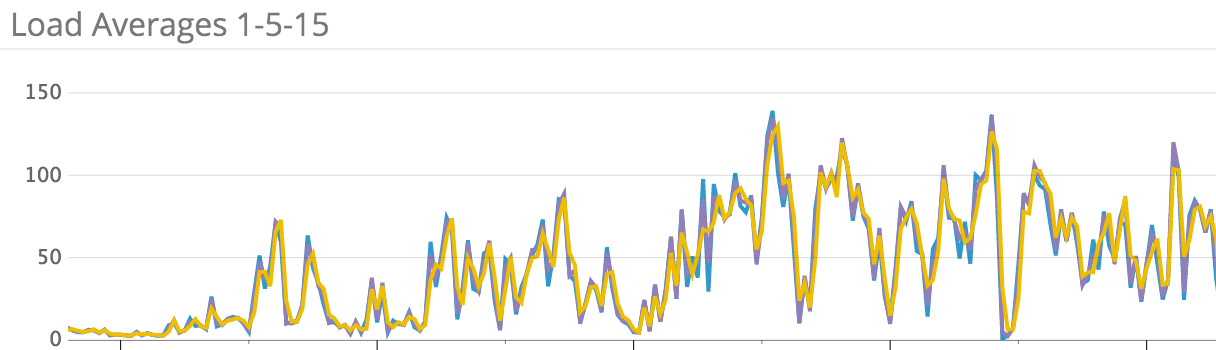
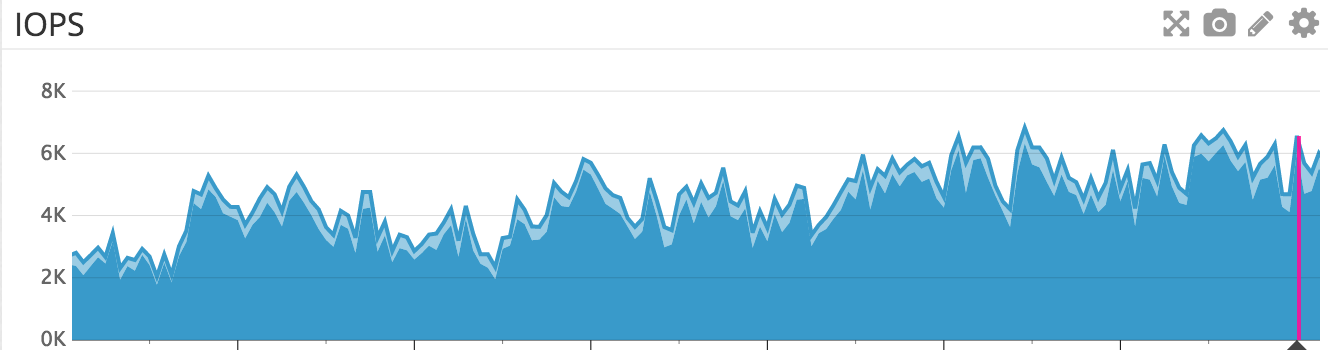
Given that nothing else was leading anywhere (and that our website was still down-ack!!), we started picking and pulling at ZoL’s command line tools, trying to get it to tell us what was wrong. Spoiler alert: we found it. However, before I explain it here, a little background on how ZoL is configured and operates for us is important.
ZoL — A Slightly Less Brief Summary of Configuration
To paraphrase Wikipedia: ZFS is a filesystem and logical volume manager rolled into one. Redundancy and protection against data corruption are it’s mission statement. Basically, a ZFS filesystem is built on top of virtual storage pools called “zpools”. Zpools are themselves comprised of ‘vdevs’, or virtual devices, which are constructed of block devices (in our case, entire hard disks). It handles all RAIDing and redundancy itself, so you can do away with expensive RAID controllers and just focus on your disks.

The way we’ve got it set up, we have vdevs comprised of 9 identical drives, 7 for storage, and 2 for parity. For simplicities sake, you can assume that each vdev, therefore, acts like its own RAID-6 device, having redundant pairs of parity disks. Pretty sweet. We stick as many of these as we need to into a zpool, on which we mount the ZFS file system. The zpools are configurable, meaning you can add new vdevs to it at any time and extend the capacity of your filesystem. ZFS does its best to fill up your vdevs at the same rate, so that they grow together, but isn’t always successful. And that is the crux of our problem.
Back to the Matter at Hand
We started our ZFS system with 2 vdevs. Over the 18 months or so between our adoption of ZFS, we had added additional vdevs to our storage servers (in the US and EU), and additional servers, to accommodate our growing storage needs. As we added more vdevs, we extended the zpool and the ZFS mount in real time, with no downtime, keeping Shapeways humming happily along. Sweet! But remember when I said that ZoL would do its level best to grow the usage of the vdevs at the same time? Turns out that starting with vdevs which were already over 70% full was too much for it to bear. What had happened to us (and which we were able to discover due to the very excellent zpool list command) was that our original two vdevs were over 99% full! This was despite the filesystem itself being less than 65% full.

Why You Have More Than One of Everything
We realized that this box was screwed. We could spend a week recopying and balancing ZoL, but we couldn’t afford that downtime. Enter: our backup servers. We had been keeping all of our backup servers up to date with the latest and greatest from our primary storage, and we had added the most recent one with all of its vdevs at once. This meant that we had a perfectly balanced copy of our entire storage on a second server, which we simply had to drop into place where the primary one resided. 30 minutes later, we were back online, hosting off of the backup server. We immediately initiated a block copy to the former primary server using ZFS send (which is a really really really cool little command) to perform a block-level copy of our entire file system from one machine to another, and got it replicating as the new backup server in that datacenter. Huzzah!
Fool Me Once, Shame on You…
We all learned quite a bit from this little exercise. The most painful lesson of all (for me, at least) was that we didn’t have the correct monitoring in place to detect this issue sooner. I have professed my adoration for Datadog more than once in the digital ink of this blog, so I wrote a Datadog check to track the usage statistics of your individual vdevs (there’s a lot of ‘em). We use this script on all of our hosts using ZoL today, and you’re welcome to check them out here. Unfortunately, ZoL requires root access (for now), so Datadog can’t accept my pull request to merge this into their default library as it’s against their policies to have their scripts running as root (fair enough!). However, you should feel free to use it if you think it’s helpful, and let me know if there’s anything I can do to make it more useful (or submit a PR if you’re hip like that).
In Conclusion
ZFS on Linux is, overall, wonderful. It works as advertised, and can save you a ton of cash on hosting your own storage through compression. It’s also got a really nice ecosystem around it to enable monitoring, reporting, and high availability should you require it. This was a small blemish on our overwhelmingly positive experience, but I wanted to be sure that we documented it to help others in the future.